
Demilka’s Skills Taxonomy is a live, skills-first intelligence framework built from more than 25 years of continuous data aggregation and analysis. It maps over 1.2 million granular skills across 20+ industries, with around 350,000 skills currently live and in demand in the market today.
Built for integration into your existing data framework, product, platform, or analytics environment, it adds a dynamic skills layer that helps organisations see beyond static classifications and broad job labels. It enables more precise skill trend analysis, richer job-to-skill and workforce-to-skill mapping, and stronger visibility across both technical and soft skills shaping current demand.
The Taxonomy powers Demilka’s own skills intelligence solutions and can also be licensed as a standalone capability, giving organisations a scalable way to embed live skills intelligence into their own systems, models, and decision-making.

The Taxonomy Engine Behind Smarter Skills Insights
Demilka deploys its taxonomy to power real-time skills intelligence—updated daily from live job data—to enable deeper, more granular analysis and clearer representation of industry demand.


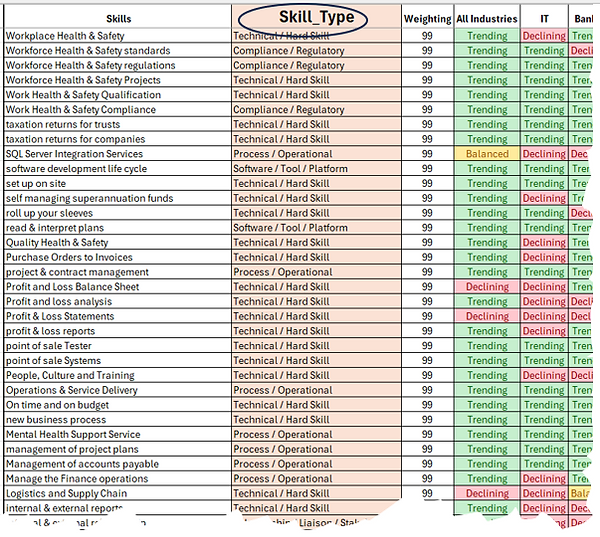







Skills Standardisation
Demilka’s Standardised Skills Taxonomy ensures consistent interpretation of skills across all levels of users by removing reliance on user spelling, phrasing, or context.
Instead of depending on input accuracy, Demilka uses advanced algorithms to convert and align skills with their intended meaning.
Skill Version & Release Differentiation
Demilka’s Taxonomy distinguishes between different versions and releases of skills, an essential capability given that each iteration can introduce meaningful changes in function, scope, or required expertise.
This level of granularity improves the accuracy of skill assessments, supports version-specific training, and informs strategic workforce planning based on current and emerging capability standards.


Disperse Multi Word Skill Linkage
occurs when parts of a multi-word skill are spread across different parts of a document, making them hard to detect.
Demilka solves this through front-end automation that detects and intelligently reconstructs separated terms into a single recognised skill entity.
Even when words appear in different sentences or sections, Demilka aligns them back to the correct taxonomy entry—preserving classification accuracy and system integrity.
Cross-Industry Skill Compatibility
Many job boards lock skills to a single industry, causing misclassification and ambiguity. Demilka enables cross-industry recognition, aligning each skill to the correct industry context for clearer, more accurate classification.
For example, “Architect” is mapped differently in Construction, Design, and IT—ensuring sector-relevant interpretation. This approach supports workforce mobility, adaptability, and better decision-making.


Child/Parent Linkage
When child skills aren’t linked to their parent categories, it leads to fragmented matches and weakens taxonomy integrity. For example, treating “Microsoft Excel 365” as standalone overlooks its connection to the broader “Microsoft Excel” skill family.
Demilka solves this through its Skill Family structure, which connects child, parent, and grandparent skills. This ensures a complete view—allowing users to trace a skill from its most specific version up to its broader category.
OSCA/ANZSCO Integration